Artificial but Natural Voices
Duration
22 months
Status
Concluded
MTC Team
Alberto Pennino, Daniel Vera Nieto, Dr. Majed El Helou, Dr. Fabio Zünd, Prof. Markus Gross
Collaborators
Christian Vogg (SRG), Florian Notter (SRF)
We explored the challenge of synthesizing speech from text and developed an AI model that generates expressive German speech from German text. We also adapt the model to produce German speech with a Swiss German accent, and address the creation of novel unique voices.

The human voice is central to almost every type of presentation. Be it the speaker on television commenting on the pictures of the latest reports, the news presenter on the radio, or a narrator in a podcast. However, automatic text-to-speech systems (TTS) have dramatically improved over the past years and are already a viable alternative to recorded human speech. End-to-end systems relying on deep neural networks and generative adversarial training have produced increasingly human-sounding speech. In this project, our main objective was to develop an open-source method capable of generating expressive unique voices out of text inputs, specifically in German and in German with a Swiss German accent.
Audio Preprocessing
To reach this goal, we have first built a data processing pipeline suitable for audio data samples. Our audio processing pipeline receives raw audio data samples, and performs the following steps: source separation, audio denoising, diarization, transcriptions, and finally embedding and clustering that can be useful for downstream machine learning tasks, analysis, and training. With source separation we decouple the audio into vocal and non-vocal elements. We then perform audio denoising to remove noise from the retrieved vocal data and enhance the quality of speech. We proceed with diarization: a necessary step of speech separation where each audio is segmented according to the different speakers present.
Subsequently, to train a TTS model, text data is necessary. We perform transcription on the extracted audio samples to obtain the needed text data. We finally extract additional information over the audio segments by performing speaker embedding and clustering to identify single speakers and/or categorical clusters of speakers. Upon surveying the state-of-the-art solutions, whether industrial or academic, we selected the best available open-source TTS method to build on, given the importance of open-sourcing for trust and transparency in media
Diffusion-Based Generation Approaches
We explored two different research directions. First, with the help of a student assistant doing an internship with us, we delved into diffusion-based spectrogram generation to integrate into pre-existing vocoder-based TTS pipelines. In TTS literature, a spectrogram is a visual representation of the spectrum of frequencies of an audio signal as it varies with time. A vocoder is a neural architecture used to generate waveform signals from spectrograms. We experimented with the introduction of diffusion-based generative processes within the spectrogram space in the VITS pipeline. Unfortunately, our experiments proved inconclusive due to the strong negative impact of the pretrained vocoders, which proved to undo any changes introduced by the previous spectrogram generation modifications.
Secondly, we explored full text-to-audio Diffusion-based generation. Given the results of our previous experiments, highlighting the limitations of pretrained vocoders, we decided to substitute the full TTS generative pipeline with a diffusion-based architecture. We tried multiple combinations of diffusion-based generators and diffusion-based vocoders. The models proved to be extremely complex and, unfortunately, never converged to a usable prototype.
VITS: Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech
Ultimately, we obtained pretrained checkpoints of the VITS model through Meta’s open-sourced MMS model, which they made available for the German language. The given checkpoints result from an extensive training procedure on Meta’s large compute resources and data: 100’000 training steps using eight V100 GPUs on a dataset of 44’700 hours. We adapted the checkpoint model through further training on Swiss German accent data: a smaller dataset of approx. 10 hours of moderations recorded by our industry partners.
We then proposed mixed-identity data training to obtain novel unique voices for our text-to-speech models. Until the end of the project, we will analyze the various facets of our model and results with a user study.
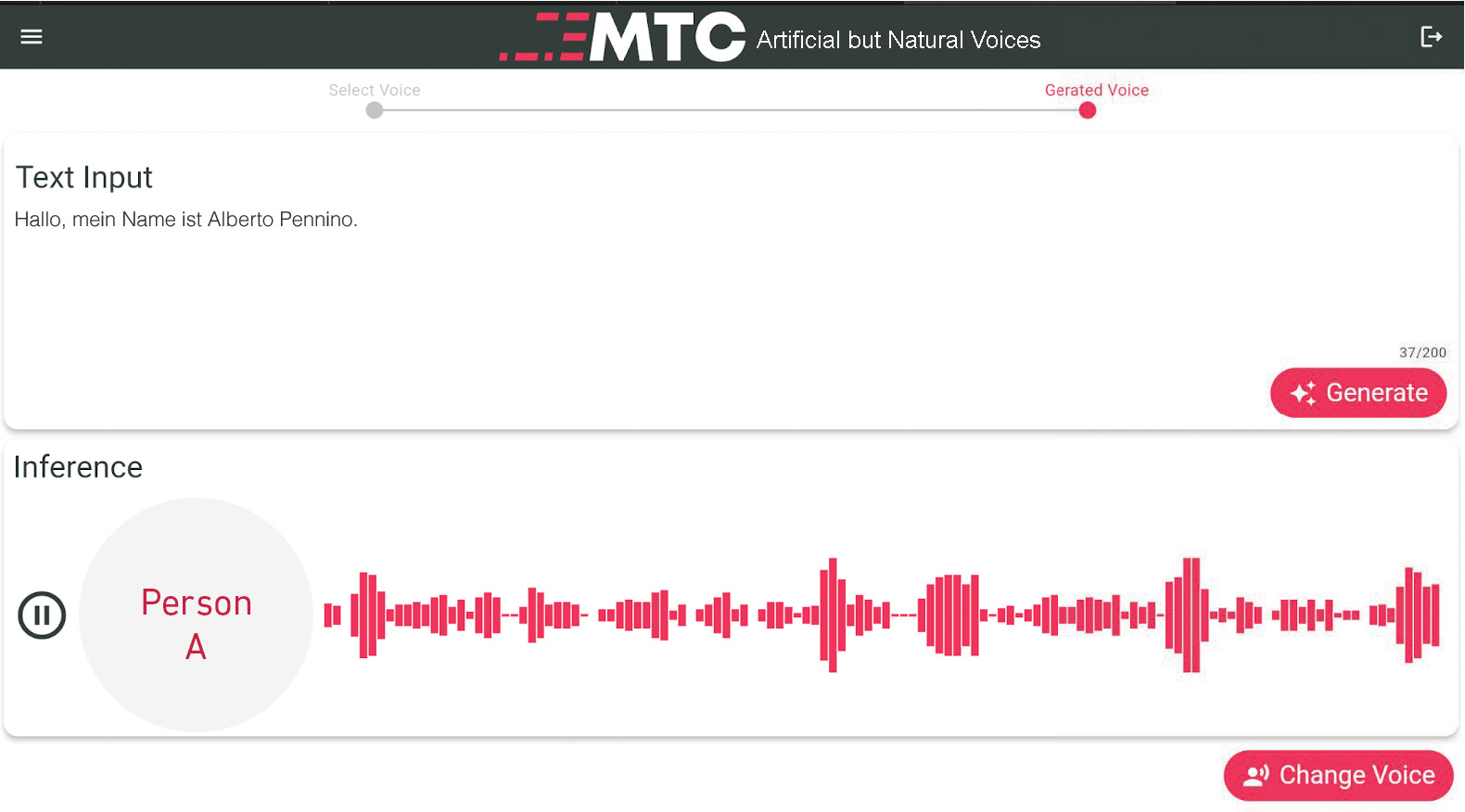
We finalized our project demo prototype for users to easily test and try out our final models. In our final prototype, users can select existing pretrained identities and listen to voice snippets. Once a voice has been selected the user can proceed to write any text and the pretrained VITS model will generate the corresponding voice.

Public Open-Source Repositories

Artificial but Natural Voices

A Text-to-speech framework for Swiss voice generation. external page Find the repository on GitHub
Artificial but Natural Voices Audio Processing

A preprocessing pipeline for preparing data collections for text-to-speech training. external page Find the repository on GitHub