Open source
At the MTC, we strongly believe in open innovation. Therefore we make our code and software available under open-source licenses to the public. Our software is typically available for commercial and non-commercial purposes at no additional cost. With our commitment to open source, we established the first step for successful technology transfers from academia to industry.
Machine Learning Frameworks / Models
We regularly release the code to any models or ML frameworks that we built as part of our projects at the MTC.
Artificial but Natural Voices

A Text-to-speech framework for Swiss voice generation. external page Find the repository on GitHub

Journalistic Portfolio Analysis
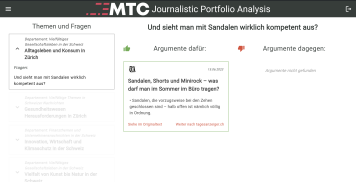
An LLM-based library for extracting debate arguments from news articles. external page Find the repository on GitHub
Low-resource Multi-document Summarization

Entropy-based sampling approaches for abstractive multi-document summarization in low-resource settings. external page Find the repository on GitHub
Guided Single-document Summarization

Implementation of the mBART model with input guidance. external page Find the repository on GitHub
Interactive Post-editing Framework

An open-source translation framework for interactive post-editing research. external page Find the repository on GitHub
Federated Neural Collaborative Filtering
A federated learning approach to neural collaborative filtering of news articles. external page Find the repository on Github
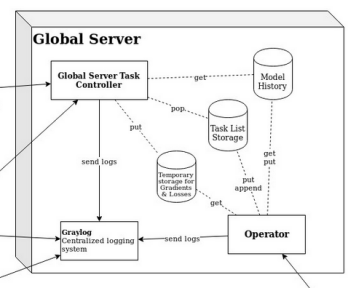
A Simple Federated Learning Framework for Small Number of Stakeholders
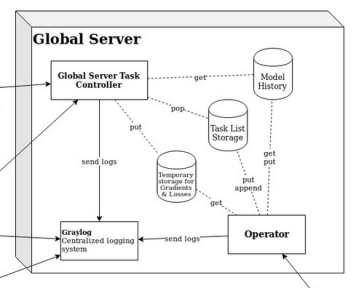
Our framework allows a small number of stakeholders to train various machine learning models in a federated way. external page Find the repository on Github
Datasets
Machine learning is driven by data. So most ML projects start with the hunt for quality datasets. We are committed to provide valuable datasets that we collect for research purposes.
Artificial but Natural Voices Audio Processing

A preprocessing pipeline for preparing data collections for text-to-speech training. external page Find the repository on GitHub
Absinth Dataset

A manually annotated dataset for hallucination detection in German news summarization. external page Find out more on GitHub
Multi-GeNews Dataset

An evaluation dataset of German news articles for abstractive multi-document summarization. external page Find out more on GitHub
Reddit Photo Critique Dataset (RPCD)

A dataset for aesthetic assessment that contains tuples of image and photo critiques. Find out more
CHeeSE Dataset

A collection of manually annotated Swiss news articles in German, where each pair of news articles and debate questions is annotated with the stance of the article towards the question, the article emotion, and the emotion of each individual paragraph. Find out more
SwissDial Dataset

An annotated parallel corpus of spoken Swiss German across 8 major dialects (AG, BE, BS, GR, LU, SG, VS, ZH). The dataset includes around 3 hours of high quality audio per dialect together with Swiss German and High German transcripts. Find out more
Data collection tools
At the MTC we are collecting data for various projects. As part of these efforts some simple-to-use data collection tools have been developed that we would like to share.
Online Text Labelling
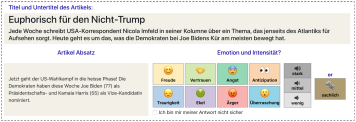
As part of our emotion & stance project we developed a streamlined web app to collect text labels. The tool was developed for news article annotation but can be easily adapted for different use cases. Find out more
Tournament-style image rating tool
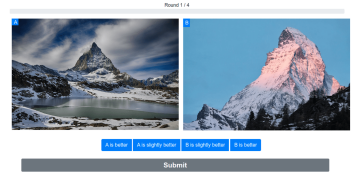
We developed a simple-to-use web tool to collect image rankings from users powered by a Swiss tournament style system. Relative user preference (one image over the other) are used to build a global ranking. Find out more
Swiss German Data Collection Tool
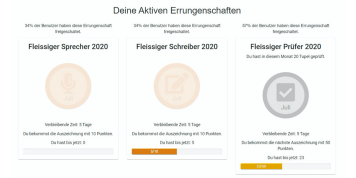
We collaborated with Fachhochschule Nordwestschweiz (FHNW) to add gamification features to their voice collection platform. Find out more